目前,随着新型冠状病毒(COVID-19)在全球范围内蔓延,海外地区现有确诊已经上升至 293683(注:数据更新至 2020.03.25 16:54)。为了更好保证自身健康,我们必须了解正在影响⽣活所在地区的实际统计数据。
如何利用现有工具来实时追踪病情分布?近日,一个有趣的开源项目正好解决了这一问题。只需一台电脑,谁都可按照步骤利用 Python 获得专属个人的疫情信息。作者发布了文章介绍该操作过程,我们将其编译如下。

Web 爬虫计划
我们将使⽤ Web 爬虫的⽅法,以及 Selenium(Web 爬虫的一个库)和 Python⼯具来完成这一计划。
首先,我们需要找到从中获取数据的网站,在本次教程中,使⽤到的是 Worldometers(https://www.worldometers.info/ ),因为作者觉得这上面的数据⾮常准确,并且⽹站看起来不错。
下面开始进入计划:

在 Worldometers 上的表格中,显示了每个受影响国家/地区的相关数据,包括:累计确诊病例、新增病例、累计死亡人数、累计治愈人数,以及病危程度的人数统计等。
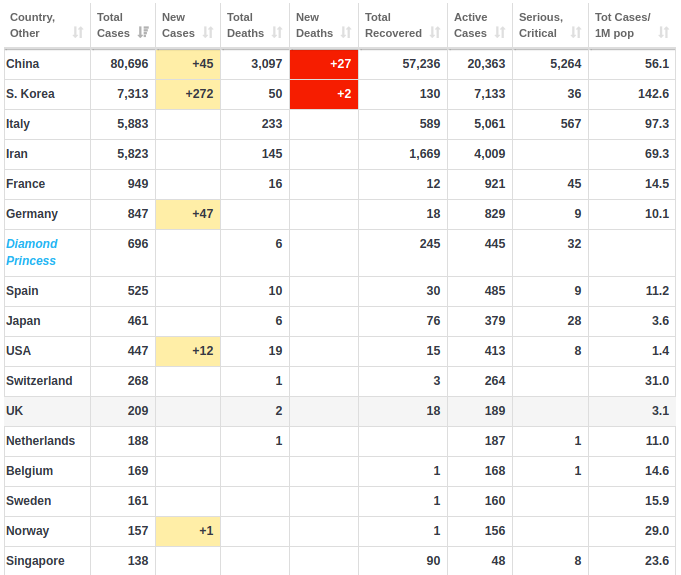
我们要做的,就是将以上的各个详细数据,通过一系列方法的转化,使其能够自动发到我们的电子邮箱中。当然,选择其它包含这些数据的网站,也不是不可以。
搭建环境
首先,我们需要安装 ChromeDriver,并进行环境搭建。
ChromeDriver 将帮助我们能够控制浏览器并向其发送命令,从而进⾏测试和之后的其它操作,可以通过链接( https://chromedriver.chromium.org/ )下载与你电脑系统相匹配的安装包。
Ps:如果你不是很熟悉 ChromeDriver,建议尽可能使用最新稳定版本。
下载之后,接下来将需要解压所下载的文件,建议右键单击「文件」,然后选择「Extract Here」,手动进行解压操作。
之后你会发现在该⽂件夹内,有⼀个名为「chromedriver」的⽂件,我们需要按照下面的步骤将其移⾄计算机上的特定⽂件夹。
-
第一步,打开终端并输⼊以下命令:
sudo su#进⼊root 模式 cd
#从当前位置返回到基础 mv / home / *your_pc_name * / Downloads / chromedriver / usr / local / bin
#将⽂件移动到正确的位置
注意:其中的「*your_pc_name *」部分,需要替换为所用计算机的实际名称。
-
第二步,打开编辑器,作者选择的是 Visual Studio Code(https://code.visualstudio.com/ )。
-
第三步,新建一个项⽬,并创建两个新⽂件。可参考下面作者的设置:
Visual Studio Code—项目设置
并且可以发现,在 VS Code 中有⼀个「Terminal」选项,可以⽤它在 VS Code 中打开内部终端。
第四步,安装虚拟环境和⽤于 Web 爬虫驱动程序的 selenium 工具,并在终端中键⼊下面这些命令:
pip3 install virtualenv
source venv / bin / activate
pip3 install selenium
最后激活虚拟环境,我们的准备工作就完成了。
开始编码
现在,我们完成对环境的搭建以及掌握所需信息获取地址后,就要开始做「编码实现」部分了。
我们将为其创建为⼀个类以及函数,使⽤任何名称创建即可,然后启动 Chrome 驱动程序:
class Coronaviru():def __init __(self): self.driver = webdriver.Chrome()然后,转到 VS Code 内部终端并输⼊下面的代码,此命令使我们可以将⽂件作为交互式场所:
python -i coronavirus.py
之后,将浏览器的新标签页打开,我们开始向其发出命令。(如果想进⾏实验,可以使⽤命令⾏代替在源⽂件中键⼊命令⾏)
对于终端,命令为:
bot = Coronavirus() bot.driver.get( https://www.worldometers.info/coronavirus/ )现在,使其获取源代码:
self.driver.get( https://www.worldometers.info/coronavirus/ )
当我们进⼊⽹站时,我们需要提取所选网页中的表格。因此,我们将以这种⽅式进⾏操作,将表格作为 Web 元素并将其保存在「表」下。
为了在⽹页上找到该元素,我们使⽤ find_element_by_xpath()并使⽤其定义的 ID 对其进⾏过滤。
table = self.driver.find_element_by_xpath( //*
[@id="main_table_countries"]/tbody[1] )
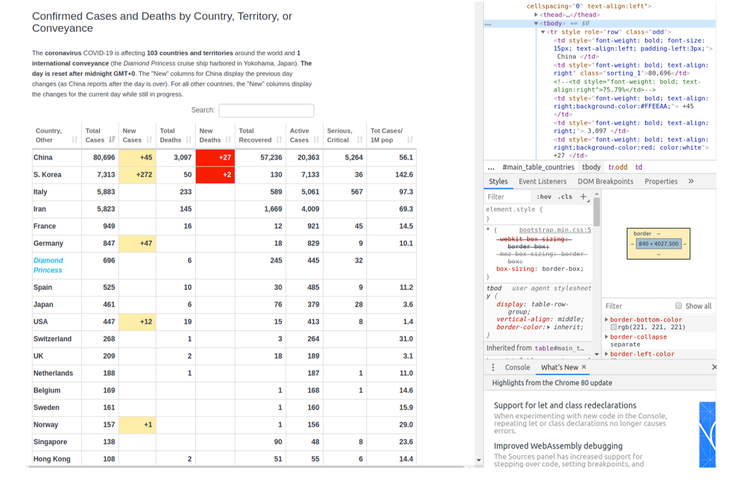
在该表中,通过对应的名称,确保要找到我们最初需要获取国家或地区。
country_element = table.find_element_by_xpath(「// td
[contains(text(), China )]」))
再次使⽤XPath,我们尝试使用「China」的数据。由于我们需要「China」旁边的数据,因此我们必须确保它属于该⾏,这就是为什么要从 country_element 中获取父节点:
row = country_element.find_element_by_xpath("./..")
在该⾏内,我们获取了所需的所有数据,我们将该字符串拆分为每⼀列,并将其保存为变量:
data = row.text.split(" ")
total_cases = data[1]
new_cases = data[2]
total_deaths = data[3]
new_deaths = data[4]
active_cases = data[5]
total_recovered = data[6]
serious_critical = data[7]
其中,「data」是⼀个来⾃字符串拆分的列表,然后我们将其分散到不同的变量中以备后⽤。
发送电子邮件
在完成编码部分之后,我们就要进入电子邮件发送部分了。

首先,需要设置电⼦邮件发送服务器。作者用到了 Google 帐户服务,然后进⼊「应⽤程序密码」,在那⾥⽣成⼀个新密码并在所写脚本程序中使⽤它。
然后,我们将通过以下代码,为我们将收到的电⼦邮件制作模板:
def send_mail(country_element, total_cases, new_cases, total_deaths, new_deaths, active_cases, total_recovered, serious_critical):
server = smtplib.SMTP( smtp.gmail.com , 587)
server.ehlo()
server.starttls()
server.ehlo()
server.login( email , password )
subject = Coronavirus stats in your country today!
body = Today in + country_element +
Total cases: + total_cases +
New cases: + new_cases +
Total deaths: + total_deaths +
New deaths: + new_deaths +
Active cases: + active_cases +
Total recovered: + total_recovered +
Serious, critical cases: + serious_critical +
Check the link: https://www.worldometers.info/coronavirus/
msg = f"Subject: {subject}{body}"
server.sendmail(
Coronavirus ,
email ,
msg
)
print( Hey Email has been sent! )
server.quit()
这样,就能够实现单次的最新疫情信息获取了。如果你希望每天重复执⾏此脚本,可以通过下面链接中的编码实现:
https://stackoverflow.com/questions/15088037/python-script-to-do-something-at-the-same-time-every-day
成功订阅!
最后,我们就得到了自制的邮件订阅啦(如下所示)。
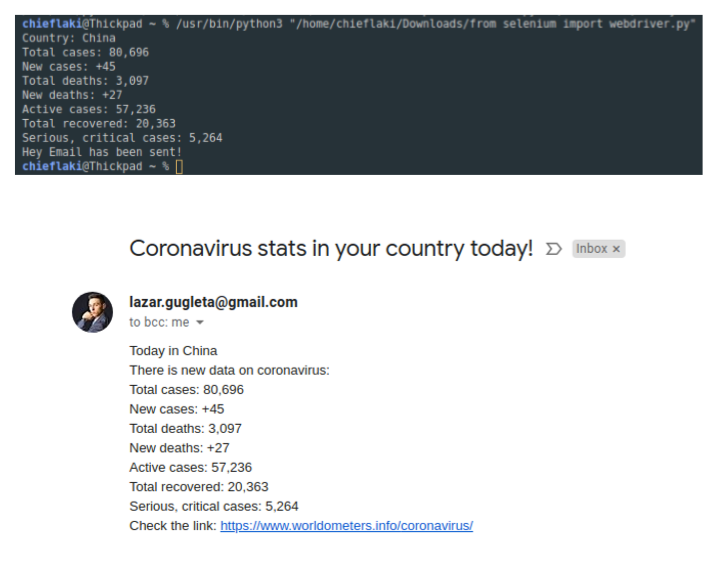
当然,除了可以将我们所在地区的新冠病毒最新情况发到个人邮箱外,通过这样的方法,举一反三,你想订阅的其它资讯也可以自定义发送,而且还没有任何广告。
而在此,也再次提醒所有朋友,在目前疫情持续情况下,一定要勤洗手、戴口罩;同时,尽可能避免与他⼈进⾏过多的⾝体接触。
原文地址:
https://towardsdatascience.com/how-to-track-coronavirus-with-python-a5320b778c8e
完整开源代码 Github 地址:
https://github.com/lazargugleta/coronavirusStats/blob/master/coronavirus.py