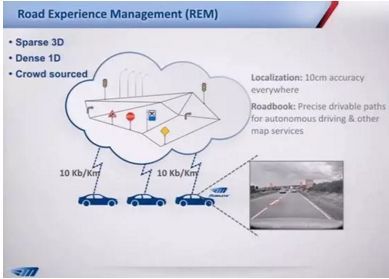
最近经常听到这样一个问题:“到底测试到什么程度,才能上路?”
测试自动驾驶的代码与测试普通互联网产品的代码不同。互联网产品的代码只要达到了目标功能,就可以发布。比如手机APP,只要用户用起来没有障碍,就是好代码。
而无人车不同。代码中存在的问题,不只是一个bug这么简单。代码中的问题,只有一小部分是“known unknown”,也就是可以预料到的问题。大多数是“unknown unknown”,也就是无法预料的问题。问题如果不被及时发现,带到了路测上,就会对公共安全造成威胁。
理论上讲,测试的环节越周密、越仔细越好。而现实中,我们往往没有足够的时间或资源去做所有的测试,或是测试所用的工具还不够成熟。因此,工程师们往往要决定,在有限的条件下,应该作何取舍。
其实,测试代码不过是为了两个目标:
1. 找到潜在的问题。
2. 有效挖出问题的根源。
针对第一个目标,我们首先要看测试的各个级别是否覆盖全面。自动驾驶的测试多种多样。首先,工程师要尽到自己份内的测试职责。从最初的几名工程师聚在一起做设计审核(design review),到基本的单元测试(unit test),再到部件测试(component-level test),工程师至少要保证自己写的那几行代码不出问题。
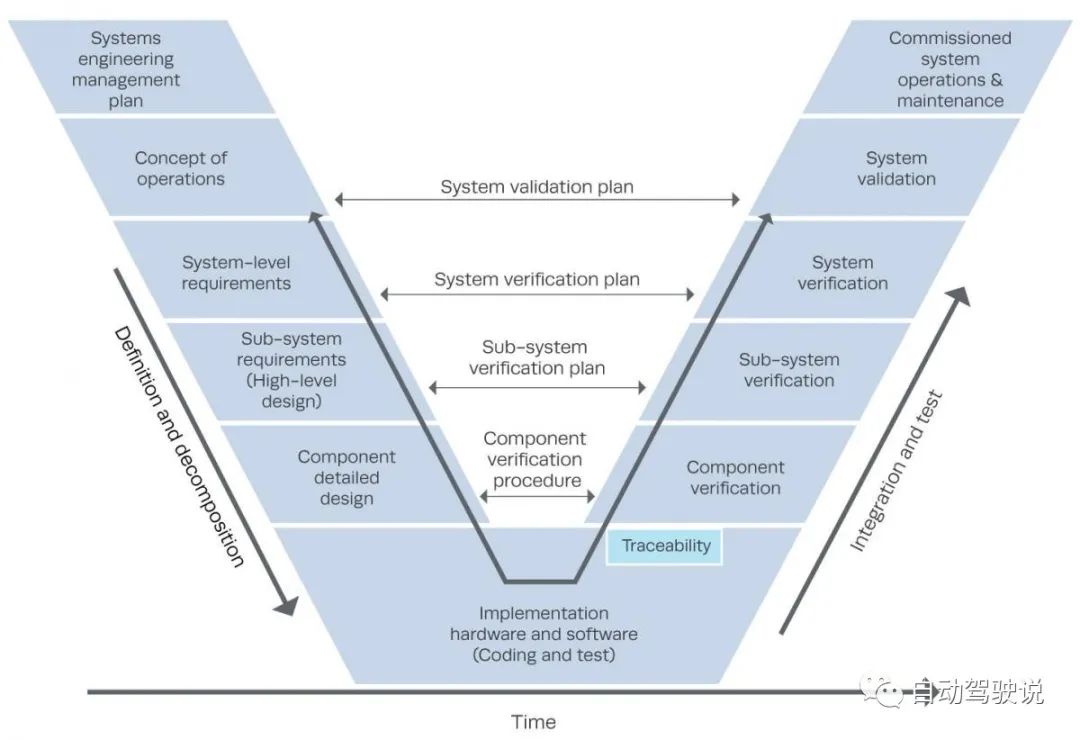
基础的测试完成之后,下一步就是保证代码与其他部件可以兼容。比如,做激光雷达模型的工程师要保证自己的代码不会影响到其他传感器。这时就需要把整个stack跑一遍,或是hardware in the loop,将其他硬件系统也一起测试,看看是否有兼容问题,做到“持续集成”(continuous integration)。具体方法可以参考V&V模型。
测试的方式也分为很多种,除了可以在本地跑代码,自动驾驶最重要的就是仿真。一个强大的仿真平台可以在一定程度上代替路测。通过仿真技术,不但可以对已有的驾驶数据(log)重演,也可以打造全新的场景,自己定义各项参数(parameter),从而让有限的数据在短时间内发挥其最大效用。
仿真测试之后,可以把代码放在车上,在封闭环境里测试(closed course),最终才可以去开放道路上测试。
测试的途径多种多样,但总体上来讲,越底层的测试,成本越低。如果等到上路测试才发现问题,那成本就很高了。
原因很简单:越底层的测试,越容易查出问题的根源。越是上层的测试,涉及的部分越广,一旦找到问题,排查起来就很难。
因此,底层的测试设计尤为重要。一个测试对象可以是一个新开发的驾驶行为,也可以是对已有功能的改进。如果是对已有功能的改进,就要将所有的细节量化为指标(metrics),指标一旦有变动,或是“退化”(regression),比如将骑自行车的人探测为行人,就要分析其原因。从而做到让每一个潜在问题都“有根可循”。
如果是开发新的驾驶功能,就可以利用仿真平台打造所需场景,预估有可能发生的问题,再针对每一个潜在的问题设计所对应的指标,做到“防患于未然”。
本内容属于网络转载,文中涉及图片等内容如有侵权,请联系编辑删除