

预测和决策两个词经常出现在我们日常生活中。平时说到的“预测”,我们通常是指对时间上晚于当下、未来将要发生的事件给出预判。“决策”通常意味着选择、决定和执行。
决策的制定依赖对未来的判断。在电影复仇者联盟中奇异博士交出时间宝石的决策,是看到了对未来14000605个结果中,唯一通向胜利结果的决策。可以看出,决策意味着改变。


同时,在我们通常的语境中,预测是可以包含决策的,例如预测股票是否会涨,这里的预测就会包含对市场交易者买卖决策的预判。
在电影少数派报告中,三位先知预测犯罪,再由乔恩预先阻止犯罪的发生;当一位先知预测乔恩将会犯罪,如果乔恩会看到预测结果则会自动停止犯罪,因此第二位先知给出了乔恩不会犯罪的预测;但因为第二位先知给出不犯罪预测,乔恩会来寻求证据,导致杀人犯罪,最终第三位先知给出了会犯罪的预测。在这个科幻故事中,可以看到在决策能够改变未来的时空下,预测变得十分困难。
在日常语境中,预测和决策常搅合在一起,界限并不是十分清晰。
在AI技术范畴中,“决策”的含义与我们日常语境中相当,例如AlphaGo每走一步的决策,都来自对很多步之后结果的评估。然而“预测”的含义则与日常语境有明显的区别。
目前几乎所有的数据驱动预测技术都依赖于独立同分布统计假设,即过去的数据跟未来的数据不会发生显著的变化,包括各种分类、回归、识别等技术。数据驱动的预测,从一批给定的训练数据中归纳模型,并根据模型对输入的数据给出判断。这一类技术实现的预测,并不是对时间上晚于当下的事件进行预判,而是训练分布下的判断。因此,只有当未来的事件与训练数据的基本一致时,才能给出准确的预测。例如短时天气预报、自然图像识别等任务就属于此类,而股票就是典型的不满足独立同分布的场景。也因此,“大数据”变得有价值,数据越多,覆盖的分布越广,对各种情况的预测就越准确。
近期关于如何打破独立同分布假设,让模型能够适应分布的变化,已经成为研究热点。然而从理论到算法都十分不容易,能广谱适应分布变化的方法还需时日。
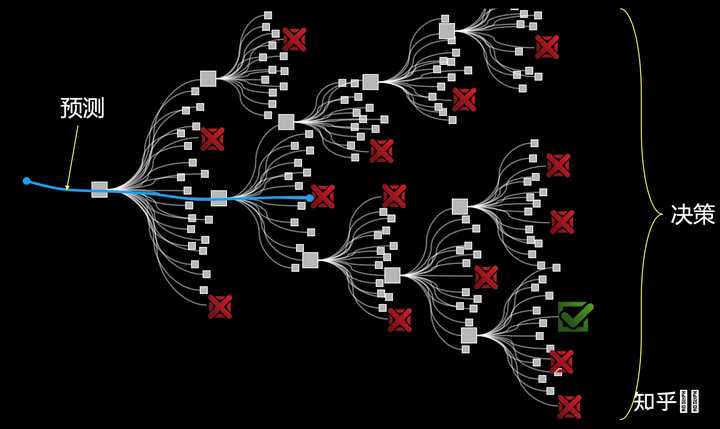

在数据分布不能变化太大的约束下,目前的预测技术很难去处理决策问题。基于过去的数据,只能预测一种未来,那就是跟过去相似的未来,而奇异博士需要看到1千4百万种未来,才能找到一个成功的决策。




